







On 13th May 2024, OpenAI announces its latest update for its ChatGPT service, GPT-4o, not an entirely new model version, but a strong update nonetheless.
GPT-4o, what’s new?
GPT-4o (“o” for “omni”) marks a significant advancement in human-computer interaction for the GPT line, accepting and generating a versatile mix of text, audio, and images in a free-flowing format. It features near-human response times to audio, averaging 320 milliseconds, and matches GPT-4 Turbo’s capabilities in English text and code while surpassing it in non-English text. GPT-4o is also offering superior vision and audio comprehension compared to existing models, all at a faster pace and 50% lower cost through the API.
Before GPT-4o, Voice Mode conversations with ChatGPT had average latencies of 2.8 seconds (GPT-3.5) and 5.4 seconds (GPT-4). This was due to a pipeline involving three separate models: one for transcription, one for text generation (GPT-3.5 or GPT-4), and one for text-to-speech conversion. This approach limited the main source of intelligence, GPT-4, by preventing direct observation of tone, multiple speakers, background noises, and the ability to express emotions like laughter or singing.
GPT-4o addresses this by training a single model across text, vision, and audio, with all inputs and outputs processed by the same neural network. As this is the first model to combine these modalities, the full extent of its capabilities and limitations are still being explored.
New capabilities
GPT-4o has a plethora of new capabilities that are steadily coming along in their effectiveness. OpenAI admits that these features aren’t yet perfect, but believes they can be refined into strong features upon public training.
Here’s just a couple of examples:
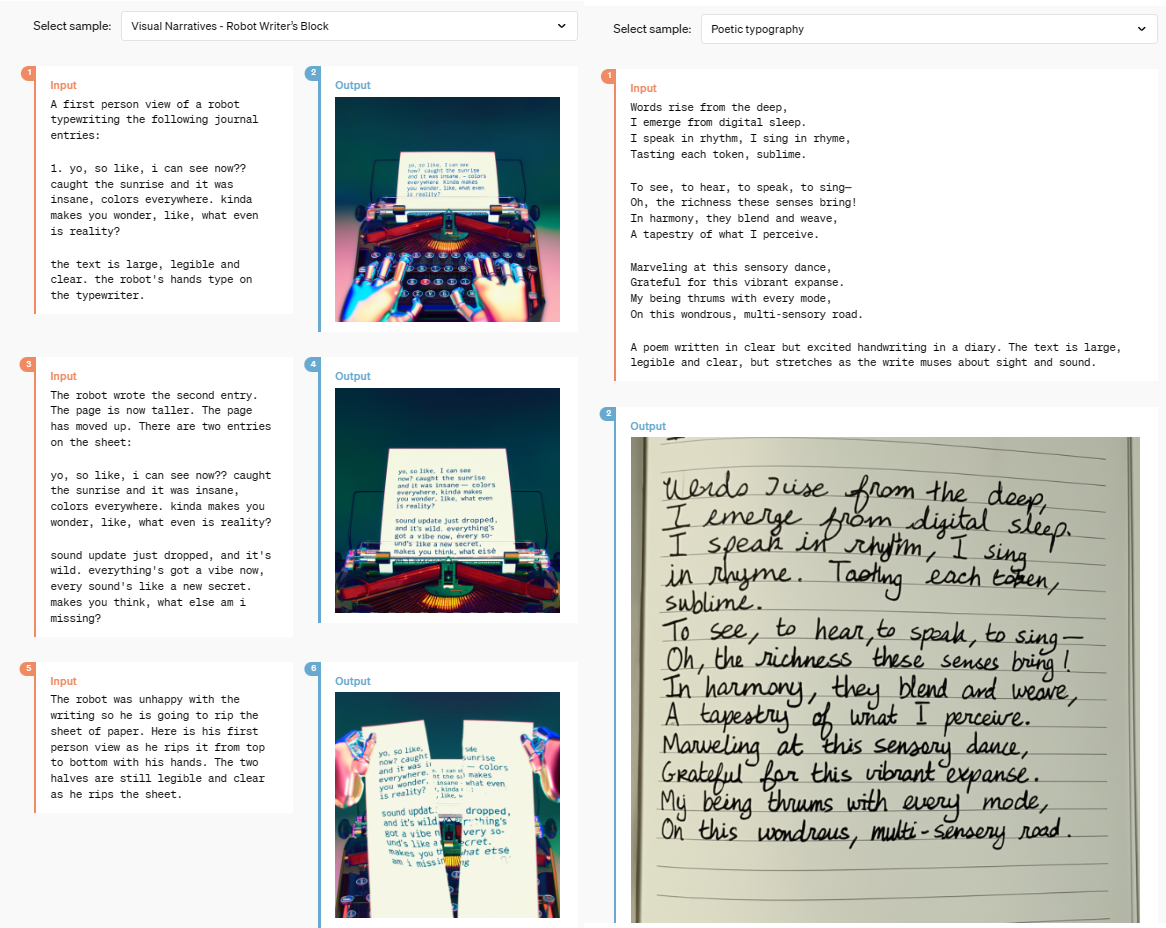
Image credit: OpenAI (Find here.)
The model was also evaluated across the board utilising various traditional benchmarks with strong performances shown in text evaluation, reasoning, audio ASR performance, audio translation, M3Exam zero-shot results, and vision understanding.
GPT-4o is also pushing boundaries in language tokenisation with big improvements to its methodology, especially amongst less common spoken languages. For example, Gujarati features 4.4x fewer tokens (from 145 to 33), Tamil features 3.3x fewer tokens (from 116 to 35), Arabic features 2.0x fewer tokens (from 53 to 26), and Vietnamese 1.5x fewer tokens (from 46 to 30).
Safety and limitations
GPT-4o integrates safety measures by design across modalities, using techniques like filtering training data and refining behaviour through post-training. New safety systems provide guardrails on voice outputs.
Evaluations following the Preparedness Framework and voluntary commitments show that GPT-4o does not exceed Medium risk in cybersecurity, CBRN, persuasion, and model autonomy. This assessment involved extensive automated and human evaluations throughout training, testing both pre- and post-safety-mitigation versions of the model.
Extensive external red teaming with over 70 experts in various domains helped identify and mitigate risks introduced or amplified by new modalities. These findings informed safety interventions to enhance the safety of interacting with GPT-4o, with ongoing efforts to address emerging risks.
Recognising the novel risks of audio modalities, the initial public release includes text and image inputs with text outputs. The technical infrastructure, usability via post-training, and safety measures for other modalities are under development. For instance, initial audio outputs will be limited to preset voices and adhere to existing safety policies. Further details on GPT-4o’s full range of modalities will be provided in the forthcoming system card.
When can I get GPT-4o?
GPT-4o’s capabilities will be introduced gradually, with expanded red team access starting from the 13th May 2024.
Text and image capabilities are now being rolled out in ChatGPT, available in the free tier and for Plus users with up to 5x higher message limits. A new alpha version of Voice Mode featuring GPT-4o will be available within ChatGPT Plus in the coming weeks.
Developers can now access GPT-4o in the API as a text and vision model, offering double the speed, half the price, and 5x higher rate limits compared to GPT-4 Turbo. Support for the new audio and video capabilities will be launched to a select group of trusted API partners in the near future.