





However, while AI models drive greater levels of accuracy than traditional methods, the complexity that accompanies sophisticated models raises an issue: How can engineers know why an AI model is making decisions, and how can they verify that these results are the ones that they expected? Johanna Pingel, AI Product Manager, MathWorks further explores.
To help unlock the ‘blackbox’ nature of sophisticated AI models, engineers can use explainable AI – a set of tools and techniques to help them understand that model’s decisions. As machine learning models arrive at their predictions, explainability can help engineers working with AI understand the how and the why behind the decision-making process.
Improving the predictive power
AI models need not always be complex. Certain models, such as temperature control, are inherently explainable due to a ‘common sense’ understanding of the physical relationships in that model. As temperature falls below a certain threshold, the heater turns on. As it passes a higher threshold, it turns off. It is easy to verify the system is working as expected based on the temperature in the room. In applications where black box models are unacceptable, simple, inherently explainable models may be accepted if they are sufficiently accurate.
However, moving to more sophisticated models allows engineers to improve predictive power. Complex models can take complex data, such as streaming signals and images, and use machine learning and deep learning techniques to process that data and extract patterns that a rules-based approach could not. In so doing, AI can improve performance in complex application areas like wireless and radar communications in a way previously not possible.
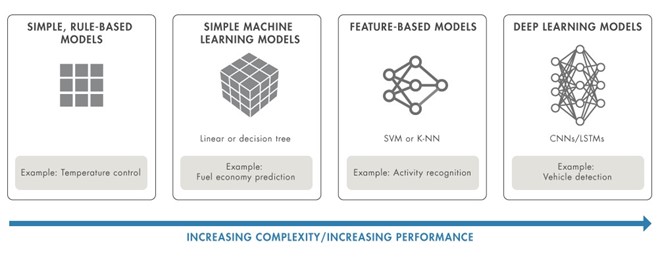
Figure 1: Evolution of AI models. A simple model may be more transparent, while a more sophisticated model can improve performance.
How can explainability help?
With complexity comes a lack of transparency. AI models are often referred to as ‘blackboxes’, with complex systems providing little visibility into what the model learned during training, or if it will work as expected in unknown conditions.
Explainable AI aims to ask questions about the model to uncover any unknowns and explain their predictions, decisions, and actions so engineers can maintain confidence that their models will work in all scenarios.
For engineers working on models, explainability can also help analyse incorrect predictions and debug their work. This can include looking into issues within the model itself or its input data. Using explainable techniques can provide evidence as to why a model chose a particular result, providing an opportunity for engineers to improve accuracy.
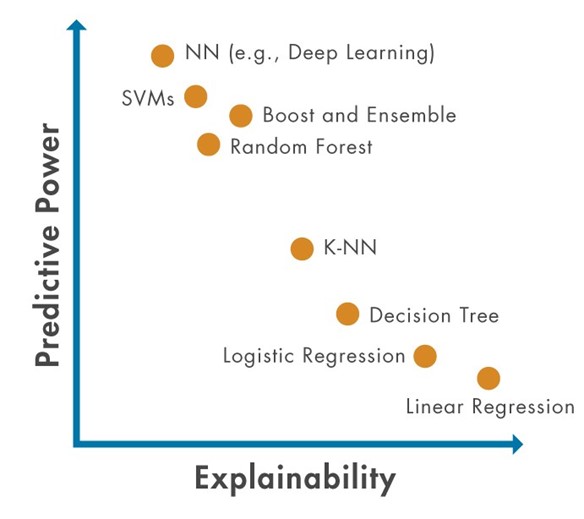
Figure 2: The tradeoff between explainability and predictive power. In general, more powerful models tend to be less explainable, and engineers will need new approaches to explainability to make sure they can maintain confidence in the models as predictive power increases.
Stakeholders beyond model developers and engineers are also interested in the ability to explain a model based on their role and interaction with the application. For example, a decision maker wants to understand how a model works with a non-technical explanation, and a customer wants to feel confident the application will work as expected in all scenarios.
As desire to use AI in areas with specific regulatory requirements to provide robustness of training increases, evidence of fairness and trustworthiness will be important for decision makers who want to feel confident that the model is rational and will work within a tight regulatory framework.
Of particular importance is the identification and removal of bias in all applications. Bias can be introduced when models are trained on data that is unevenly sampled and could be potentially concerning for models applied to people. Model developers must understand how bias could implicitly sway results to ensure AI models provide accurate predictions without implicitly favouring particular groups.
Current explainability methods
To deal with issues like confidence in models and the possible introduction of bias, engineers can leverage explainability methods into their AI models. Current explainable methods fall into two categories – global and local.
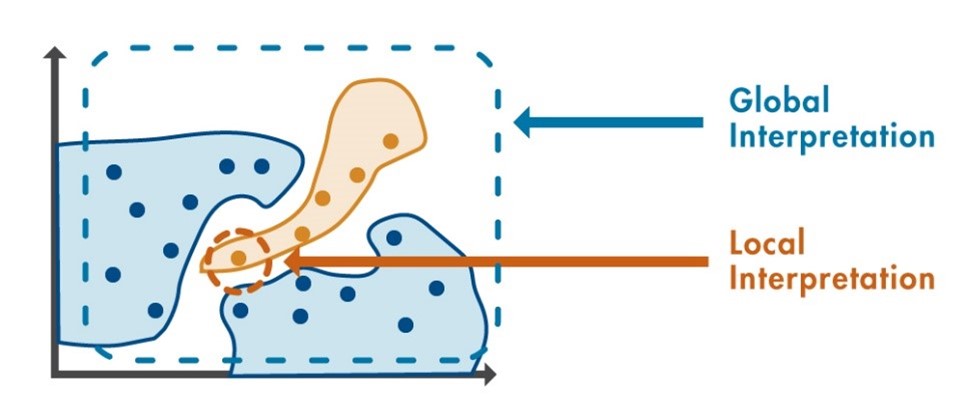
Figure 3: The difference between global and local methods. Local methods focus on a single prediction, while global methods focus on multiple predictions.
Global methods provide an overview of the most influential variables in the model based on input data and predicted output. For example, feature ranking sorts features by their impact on model predictions, while partial dependence plots chart a specific feature’s impact on predictions across the whole range of its values.
Local methods like Local Interpretable Model-agnostic Explanation (LIME), provide an explanation of a single prediction result. LIME approximates a complex machine or deep learning model within a simple, explainable model in the vicinity of a point of interest. By doing so, it provides visibility into which of the predictors most influenced the model’s decision.
Visualisations are another powerful tool to assess model explainability when building models for image processing or computer vision applications. Local methods such as Grad-CAM identify locations in images and text that most strongly influenced the prediction of the model, while global T-SNE uses feature groupings to displayhigh-dimensional data in an easy-to-understand two-dimensional plot.

Figure 4: Visualisations that provide insight into the incorrect prediction of the network.
Looking beyond explainability
While explainability may overcome stakeholder resistance against black box AI models, this is only one step towards confidently using AI in engineered systems. AI used in practice requires models that can be understood and constructed using a rigorous process, and that can operate at a level necessary for safety-critical and sensitive applications. For explainability to truly embed itself in AI development, further research is needed.
This is shown in industries such as automotive and aerospace, which are defining what safety certification of AI looks like for their applications. Traditional approaches replaced or enhanced with AI must meet the same standards and will be successful only by proving outcomes and showing interpretable results. Verification and validation research is moving explainability beyond confidence that a model works under certain conditions, working instead to ensure that models used in safety-critical applications meet minimum standards.
As the development of explainable AI continues, it can be expected that engineers will increasingly recognise that the output of a system must match the expectations of the end user. Transparency in communicating results with end users interacting with these AI models will therefore become a fundamental part of the design process.
Is explainability right for your application?
The future of AI will have a strong emphasis on explainability. As AI is incorporated into safety-critical and everyday applications, scrutiny from both internal stakeholders and external users is likely to increase. Viewing explainability as essential benefits everyone. Engineers have better information to use to debug their models and ensure the output matches their intuition, while also gaining more insight into their model’s behaviour to meet strict compliance standards. AI is likely to only get more complex, and the ability of engineers to focus on increased transparency for these systems will be vital in the forward evolution of AI.
To hear more on explainable AI, listen to Editor Paige West’s podcast with Johanna Pingel.