





What we know as traditional memory and storage systems are not designed to address the challenge of accessing these large data sets, so a key hurdle for AI and machine learning applications entering the IT mainstream is reducing the overall time to discovery and processing to ensure the success of these systems’ operation.
Before going into details about why memory and storage are essential for your AI and ML applications, it’s important to understand how they work. Memory, or more specifically DRAM, is needed as a place to keep data that needs to be transformed as fast as possible into useful information. Storage, or more specifically Flash, is needed to store both raw data and data that has been transformed so that it is not lost. The basic process for memory and storage of data is ‘ingest, transform, and decide’ – as fast as possible.
Servers and AI
Servers used for AI development have shifted from a configuration centered on CPUs to those centered on multiple GPUs. AI servers have significantly more compute and memory content relative to traditional servers required for their multiple and rapid workflows. AI development is driving content higher across the hardware landscape as developers move from traditional architectures to ones that leverage new technologies to accelerate workflows.
According to Gartner, a leading research and advisory company that provides business insights for enterprise technology businesses, both inferencing and training servers offer increased processing speeds for memory and storage for AI and ML applications.
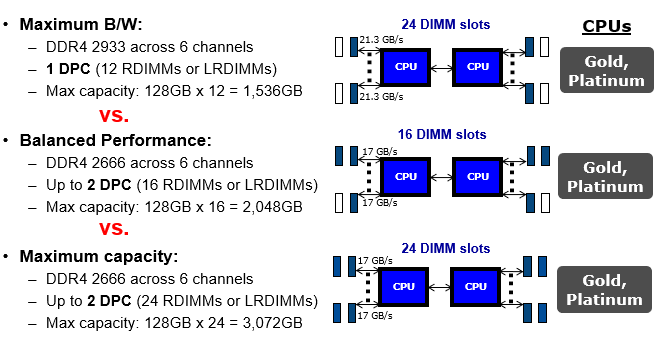
Above: Figure 1. Bandwidth vs performance DIMM population chart for Intel Cascade Lake CPUs
Inferencing servers: according to Gartner, use a trained machine learning algorithm to make a prediction. IoT data can be used as the input to a trained machine learning model, enabling predictions that can guide decision logic on the device, at the edge gateway or elsewhere in the IoT system. These servers offer significantly improved processing performance, approaching 20% more DRAM than a standard server.
Training servers: Nvidia-powered GPU servers for example, tied together into large training networks for AI software, are what enable Facebook products to perform object and facial recognition and real-time text translation, as well as describe and understand the contents of photos and videos. Capabilities learned during deep learning training are put to work. Training Servers utilise accelerator cards from Nvidia as an example and offer approximately 2.5 times more DRAM than a standard server.
DRAM memory for AI
Higher memory bandwidth and low latency are required for better performance of parallel computing using GPUs, offering the required increase in bandwidth, processing speeds and workflows required for AI and ML applications. The goal is to get from raw data to analytics to action with the lowest latency. The GPUs used in the training servers need to be paired with the right type and amount of memory to optimise performance. Different GPUs have different memory requirements. In an example AI system, Nvidia’s DGX-1 has 8 GPUs each with 16GB of internal memory.
The system’s main memory requirement is 512GB consisting of 16x32GB DDR4 LRDIMMs. LRDIMMs are designed to maximise capacity and bandwidth in AI servers, especially when CPUs do not provide enough memory channels to accommodate more than 8 RDIMMs. This is the limitation with the Broadwells CPUs that are situated inside the DGX-1.
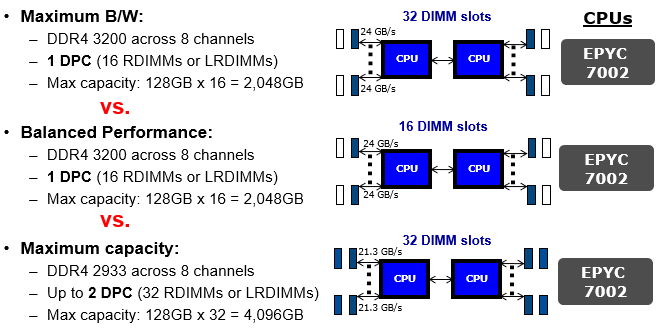
Above: Figure 2. Bandwidth vs performance DIMM Population Chart for AMD Rome CPUs
Different memory types and DIMM population scenarios in servers require tradeoffs between performance and capacity. LRDIMMs are designed to minimise loading while maximising capacity. LRDIMMs use a buffer chip for scalable performance. RDIMMs are typically faster and improve signal integrity by having a register on the DIMM to buffer the address and command signals between each of the DRAMs on the DIMM and the memory controller.
This permits each memory channel to utilise up to three dual-rank DIMMs. LRDIMMs use memory buffers to consolidate the electrical loads of the ranks on the LRDIMM to a single electrical load, allowing them to have up to eight ranks on a single DIMM module. With RDIMMs, system performance decreases when all the sockets are fully populated. This occurs in Broadwell CPUs and previous generations of Intel CPUs. With Skylake and Cascade Lake generation of Intel CPUs, the memory channel limitations are no longer present. The same goes for the AMD Rome and Milan generations of CPUs. Therefore, RDIMMs are the fastest solution that is available on the market.
Flash storage for AI
According to The Register, ‘Flash, with its combination of low latency and high throughput, is currently considered the most optimal solution for AI storage, although a great deal also depends upon the way the storage subsystem is implemented. In general, a disk array may have a latency of tens of milliseconds, while that of Flash is typically in tens of microseconds, or about a thousand times faster. ’
These significantly increased processing speeds are required to perform the multiple tasks required in most AI and ML uses.
Flash as a storage solution brings several benefits and advantages to these AI and ML applications. Flash’s ability to manage throughput of data with low latency means applications can access and process data faster, and process requests in parallel.
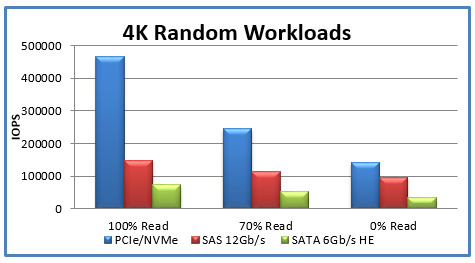
Above: Figure 3. Performance comparison between SATA and NMVe-based SSD built-on 4K random workloads
The design of Flash storage, in comparison to traditional read/write hard drives, allows it to find and process data much more quickly, ‘as it takes exactly the same time to read from one part of the chip as any other, unlike hard drives where the rotation of the disk surface and the time taken to move the read/write heads above the correct cylinder on the disk causes varying delays.’ Flash storage also requires lower power for usage, which can save costs for those applications or enterprise users that require large scale storage solutions.
NVMe SSDs are the optimal choice for AI and ML servers vs. SATA SSDs. NVMe storage avoids the SATA bottleneck by connecting via PCIe (Peripheral Component Interconnect Express) buses directly to the computer’s CPU. A NVMe-based drive can write to disk up to 4x faster and seek times are up to 10x faster. NVMe SSDs have optimised read/write requests. SATA drives support a solitary I/O queue with 32 entries. NVMe-based SSDs support multiple I/O queues with a theoretical maximum of 64,000 queues, each permitting 64,000 entries for a total of 4.096 billion entries. The NVMe drive’s controller software is also designed to create and manage I/O queues.
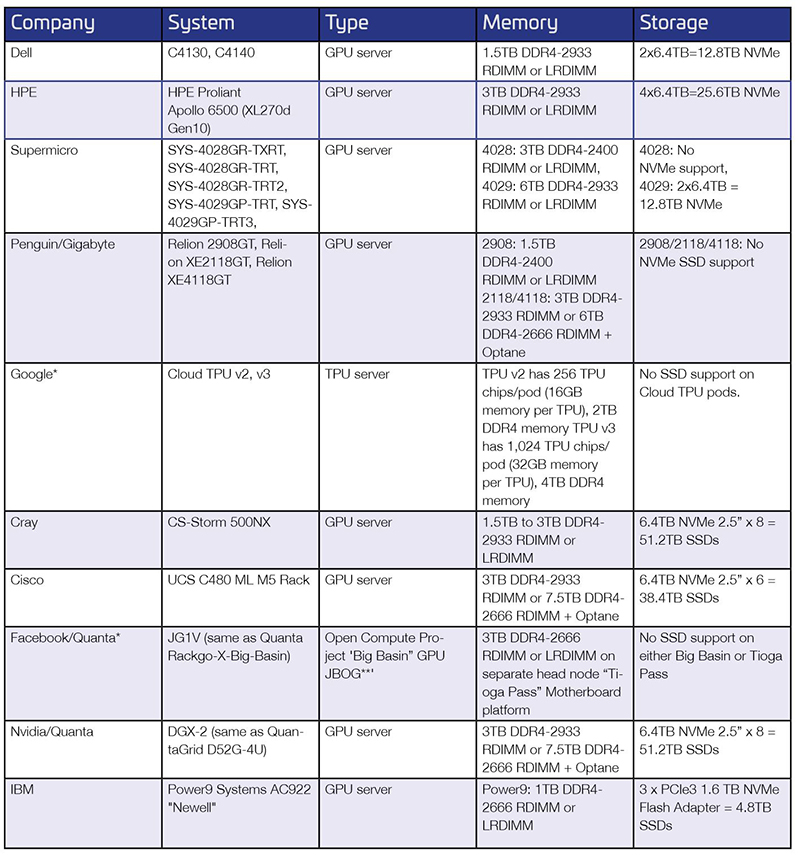
Above: Figure 4. Memory and storage requirements for AI servers at-a-glance
Lastly, the table left (Figure 4) outlines the types and densities of memory and storage used in some common AI servers. AI and ML application designers are well-served to consider the specifications of the memory and storage solutions incorporated into their applications, as this can make the difference between performance and optimal performance to meet the demands of the application and its users. Memory and storage need to perform ‘ingest, transform, and decide’ operations as fast as possible. This can be the difference between the success or failure of your application.