





As real-time distributed systems become increasingly complex, as are the factors that affect the performance of the systems during modelling and testing. Extrapolating results from simplistic performance tests or non-representative software deployments must be done carefully. Before users can rely on the results of any benchmark testing, they must ensure that the test conditions are applicable to their application architecture and design. As an example, ROS 2 systems are almost always built using multiple processes which allow the system to be lean, modular, and maintainable. Thus, test conditions should always reflect multiple processes. In addition, more accurate results come through representative, real-world setups that include scalability requirements, large data sets and a many-to-many topology.
A top performance is critical to every project. RTI Connext DDS has been designed to provide throughput that both scales with payload size and delivers very low latency. So how does Connext perform in real-world conditions?
Integrated benchmark applications
The most-common applications for testing ROS 2 Middleware Wrapper (RMW) performance share a common design and code base. We’ve used the same test run on the ROS 2 nightly CI build site to replicate their posted results, and have noted:.
- The ROS 2 nightly performance is using an older (and now obsolete) “rmw_connext_cpp.” RMW. This was the first RMW-DDS layer developed and has known performance issues caused by unnecessary memory allocations and copies done in the RMW layer itself. This has now been fixed in two new RMW called “rmw_connextdds” and “rmw_connextddsmicro” both contributed by RTI, which are being included in the ROS 2 nightly builds
- The nightly-build test runs everything in a single-process; however, most ROS 2 systems are composed of multiple processes.
So why does this matter? Communication between application threads in a single process doesn’t require middleware. Threads can exchange data and data-references directly over the common memory space provided by the process. Therefore, performance test results run using a single process are not representative of what realistic systems will see.
Testing a more realistic ROS 2 system
Let’s try a benchmark test that looks more like a ROS 2 system that we’ve seen in actual production environments. The popular benchmark test programs are complicated, and don’t look like ROS2 applications, whereas the test used for this article looks like a ROS2 application and is very easy to understand (fewer than 100 lines of source code) The test is composed of three types of ROS 2 nodes (SOURCE, WORK, SINK) which run in separate processes, each measuring the latency of the underlying RMW implementation as data is passed through the system.
This test is designed to support many different system configurations, by arranging as many SOURCE, WORK, and SINK nodes as needed: For this test, we’ll be using a simple SOURCE–>SINK arrangement (without any WORK nodes) to match the primary configuration of the nightly ROS 2 build test.
The test application is built as a normal ROS 2 package, just like any other ROS 2 application: This is far from a comprehensive benchmark test, but it is more closely aligned with real-world ROS 2 systems and already produces some interesting, non-intuitive results.
Comparing the results
One of the more noticeable results is the vast improvement in performance from the two new RMWs for RTI Connext: (Fig. 1)
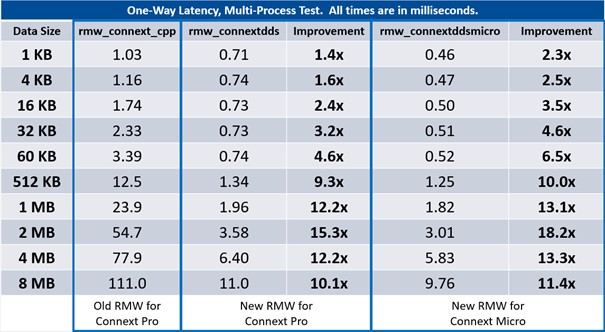
The new RMWs for RTI Connext Professional and Micro achieve a huge improvement in performance
Connext DDS Micro scores the best multi-process results across all data sizes and Connext DDS Professional brings next-best multi-process performance with large data sample sizes. (Fig. 2)
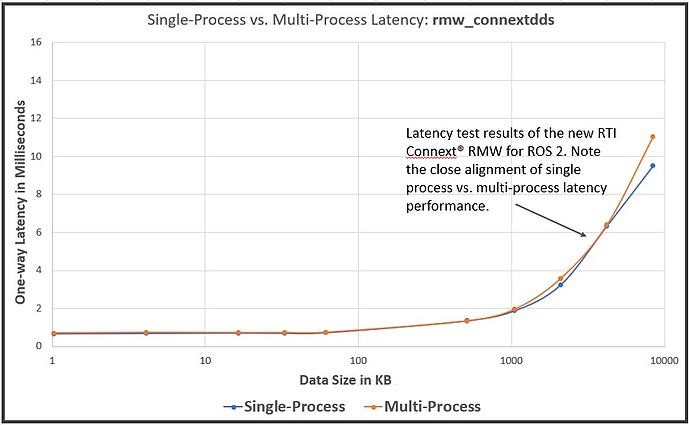
The latency test results of the RTI Connext RMW for ROS 2 show high consistency in single-process and multi-process performance
The second observation is the poor correlation of multi-process and single-process test results for some RMW implementations, but not for Connext: Some RMWs that exhibit good performance in single-process results are actually the worst performers when running the same test in multiple processes. This is due to the use of ‘Local Delivery’, a shortcut that detects if the data destination is in the same process as the source, it will bypass the network stack and move the data directly to its destination.
Local delivery in a single process application has its uses, but most of the time it will not be representative of a deployed system. And if you were architecting that system that depended on deploying multiple ROS nodes in the same process and needed to squeeze that extra bit of large-data performance, you could also get it by sending a data-pointer rather than the data itself.
Connext DDS also supports a Zero Copy mode that can get the increased performance when sending large data inside a Process or over shared memory. Moreover, the Zero Copy approach used by Connext does not ‘bypass’ the serialisation and protocol and therefore does not cause the undesirable ‘coupling’ side-effects. However, the Connext Zero Copy utilises a specialized API that cannot be mapped to the ROS RMW API. You can explore the benefits of the Zero Copy feature as well as more extensive performance scenarios using rtiperftest (the RTI performance benchmarking tool).
Benchmarks can be valuable if they are conducted under realistic conditions to your use case.
