

Dozens of customers are already deploying the CEVA-XM4 and CEVA-XM6 vision platforms along with the CDNN neural network software framework in consumer, surveillance and ADAS products. This new family of dedicated AI processors offers a considerable step-up in performance, ranging from 2 Tera Ops Per Second (TOPS) for the entry-level processor to 12.5 TOPS for the most advanced configuration.
The NeuPro processor line extends the use of AI beyond machine vision to new edge-based applications including natural language processing, real time translation, authentication, workflow management, and many other learning-based applications that make devices smarter and reduce human involvement.
Ilan Yona, Vice President and General Manager of the Vision Business Unit at CEVA, commented: “It’s abundantly clear that AI applications are trending toward processing at the edge, rather than relying on services from the cloud. The computational power required along with the low power constraints for edge processing, calls for specialised processors rather than using CPUs, GPUs or DSPs. We designed the NeuPro processors to reduce the high barriers-to-entry into the AI space in terms of both architecture and software. Our customers now have an optimised and cost-effective standard AI platform that can be utilised for a multitude of AI-based workloads and applications.”
The NeuPro architecture is composed of a combination of hardware-based and software-based engines coupled for a complete, scalable and expandable AI solution. Optimisations for power, performance, and area (PPA) are achieved using a precise mix of hardware, software and configurable performance options for each application tier.
The NeuPro family comprises four AI processors offering different levels of parallel processing:
- NP500 is the smallest processor, including 512 MAC units and targeting IoT, wearables and cameras
- NP1000 includes 1024 MAC units and targets mid-range smartphones, ADAS, industrial applications and AR/VR headsets
- NP2000 includes 2048 MAC units and targets high-end smartphones, surveillance, robots and drones
- NP4000 includes 4096 MAC units for high-performance edge processing in enterprise surveillance and autonomous driving
Each processor consists of the NeuPro engine and the NeuPro VPU. The NeuPro engine includes the hardwired implementation of neural network layers among which are convolutional, fully-connected, pooling, and activation. The NeuPro VPU is a cost-efficient programmable vector DSP, which handles the CDNN software and provides software-based support for new advances in AI workloads.
NeuPro supports both 8-bit and 16-bit neural networks, with an optimised decision made in real time in order to deliver the best tradeoff between precision and performance. The MAC units achieve better than 90% utilisation when running, ensuring highly optimised neural network performance. The overall processor design reduces DDR bandwidth substantially, improving power consumption levels for any AI application.
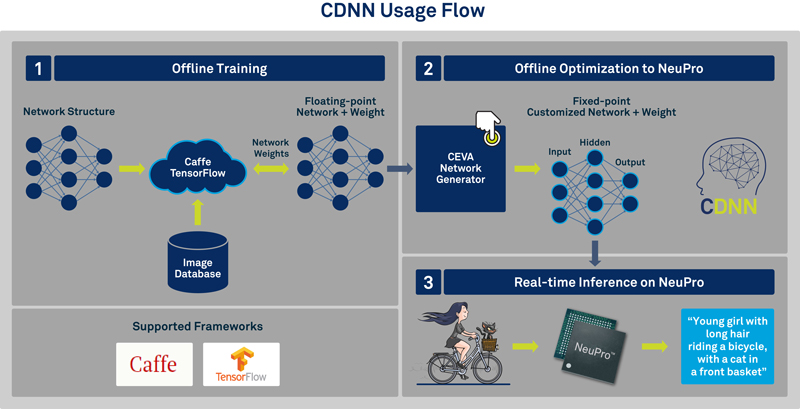
The NeuPro family, coupled with CDNN, CEVA’s award winning neural network software framework, provides the ultimate deep learning solution for developers to easily and efficiently generate and port their proprietary neural networks to the processor. CDNN supports the full gamut of layer types and network topologies, enabling fastest time-to-market.
In conjunction with the NeuPro processor line, CEVA will also offer the NeuPro hardware engine as a Convolutional Neural Network (CNN) accelerator. When combined with the CEVA-XM4 or CEVA-XM6 vision platforms, this provides a flexible option for customers seeking a single unified platform for imaging, computer vision and neural network workloads.