




I recently moved and found myself looking for a screwdriver. Five minutes later I was looking for a letter opener. Towards the end of the unpacking day, I found myself looking for a can opener. I realised that I had been using very specific tools for each task. My friend, observing this, gifted me a Swiss Army knife.
The knife had everything I needed, and as new needs arose, it had something for those too. What if I told you Xilinx’s Adaptable Compute Acceleration Platform (ACAP) is a Swiss Army knife for Artificial Intelligence (AI) and more?
AI-based systems in the fields of industrial and healthcare are increasingly moving from research projects and prototypes to the productisation phase. This demands key requirements which are unique to edge devices such as more computation and performance at low price, power and latency. Additionally, AI scientists are constantly innovating to bring out newer algorithms and models that require different hardware architectures to be optimal.
Xilinx’s Adaptable Compute Acceleration Platform (ACAP) can be used to accelerate core industrial and healthcare functionality in applications like motor control (control algorithm), robotics (motion planning), medical imaging (ultrasound beamforming), etc. but this article’s focus is on AI.
Xilinx and today’s AI
Xilinx was catapulted into the forefront of AI inference with the acquisition of Deephi and the adaptable compute nature of Zynq UltraScale+ MPSoC. Deephi presented the world’s first paper on Compressed and Sparse Neural Networks ‘Deep Compression’, a technique that aims to compress neural networks by an order of magnitude without losing prediction accuracy (models that underwent Deep Compression show up to 3-4x speed-up in inference and 3-7x better energy efficiency).
Xilinx Zynq UltraScale+ MPSoC core components include Application Processors (Arm Cortex-A53), Real-Time Processors (ARM Cortex-R5) and Programmable Logic (PL). This platform allowed the compressed output neural networks to be deployed on Deep Learning Processing Units (DPU), which were implemented in PL and accelerated the compressed neural networks to extract more performance from them. Since DPUs are implemented in PL, it has variants of sizes for different levels of parallelism and could be deployed as single, double or triple cores and beyond, based on the hardware resources available in the platform that you choose.
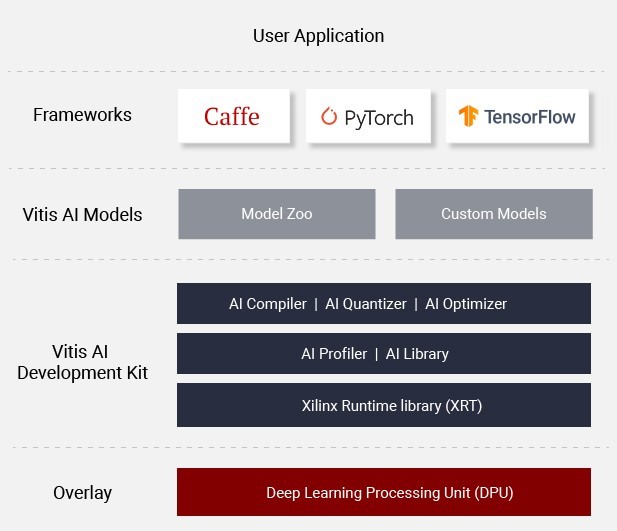
Above: Xilinx Vitis AI Development Platform for AI Inference on Xilinx Hardware Platforms
Further utilising the adaptable compute nature, in 2017, Xilinx published an INT8 DPU, moving from Floating point (FP32) to Integer (INT8) to reduce memory storage and bandwidth while maintaining good accuracy.
Then came the next big but very important challenge: AI scientists who work with a large number of Deep Learning Frameworks (TensorFlow, Caffe, Darknet, etc.) want to try out multiple hardware platforms within the Xilinx portfolio to find the best fit for their use case. Furthermore, they want to develop in a language they are most familiar with.
In 2019, Xilinx addressed these needs by introducing a unified tool called Vitis AI that works with models from popular deep learning frameworks and targets any device across the Edge portfolio or the Cloud portfolio using common programming languages. In addition, Vitis AI comes with 50+ Open Source pre-trained and pre-optimised AI models (Xilinx Model Zoo) that can be retrained with a custom dataset, allowing AI software developers to start at a much-elevated starting point, when compared to training and optimising the model from scratch.
Key Benefits of Xilinx in today’s AI:
- Reduction in resource utilisation: Lower precision (INT8) compressed neural networks meant fewer DSP, look-up tables (LUTs) and smaller memory footprint.
- Lower power consumption: Less resource utilisation inherently leads to lower power.
- Reduced BOM cost: Use additional available resources to include extra features at the same cost.
- Support for Deep Learning Frameworks: Caffe, PyTorch and TensorFlow.
- Unified Development Tool: Target any device across Edge and Cloud using Xilinx Vitis and Vitis AI.
- Minimal change to AI Software Developer Workflow.
Xilinx and tomorrow’s AI (two knives of many)
As a technology provider that has a significant play in today’s AI and the power of adaptable compute from its hardware platform, Xilinx is continuously working on tomorrow’s AI. In this section, two of the many future adaptable compute approaches being worked on by Xilinx are discussed:
- INT4 DPU
- FINN – Fast, Scalable Quantised Neural Network Inference
Note: The approaches discussed in this section are not currently productised by Xilinx but are being discussed in the article to demonstrate the adaptable compute capabilities of Xilinx’s hardware platform.
A. INT4 DPU: In the previous section, the Xilinx Vitis AI and INT8 DPU were discussed. INT8 provides significant performance improvements compared to floating point for AI inference. Looking forward to future performance requirements for the Edge where higher performance and low latency is desired at lower or the same resource limits, INT4 optimisation is the answer. Imagine a scenario where the hardware can improve over time. Existing Xilinx devices deployed to the field can be upgraded from INT8 DPUs to INT4 DPUs to achieve up to a 77% performance boost on hardware at less logic and on-chip memory utilisation.
The first step towards deploying neural networks on the INT4 DPU is to make the whole quantisation process hardware friendly. The INT4 quantisation method can be split into three categories:
1. Quantisation Mechanism
2. Hardware-Friendly Quantisation Design
3. Quantisation-Aware Training
Xilinx uses the Quantised-Aware Training (QAT). It is the key technology used to reduce the accuracy gap between low-bit and full-precision. Among QAT, the algorithm of choice is Layer-Wise Quantisation Aware Training. This method can be used for image classification, pose estimation, 2D and 3D detection, semantic segmentation and multi-tasking.
The rest of the development flow is the same – users will take the trained model and run it through the Xilinx Vitis AI to obtain a deployable model for the target platform. INT4 DPU performance improvements are in the range of 15.X to 2.0X compared to the INT8 DPU, in additional to already seen benefits of lower bit inference like reduced resource utilisation, lower power consumption, reduced BOM cost, support for popular deep learning frameworks and programming languages.
B. FINN: The first paper on the FINN project by Xilinx Research Labs was published in 2017. This article discusses the second generation of the FINN framework (FINN-R), an end-to-end tool which enables design space exploration and automates the creation of fully customised inference engines on a Xilinx hardware platform.
FINN-R has one key goal: given a set of design constraints and a specific neural network, what is the best hardware implementation that can be achieved and automates this goal so users can immediately realise its benefits on their Xilinx hardware platform? Like Vitis AI, FINN-R supports multiple popular deep learning frameworks (Caffe, TensorFlow, DarkNet) and allows users to target a variety of hardware platforms across Edge and Cloud (Ultra96, PYNQ-Z1 and AWS F1 instance).
How does FINN-R achieve this goal? The answer lies in the full inference accelerator architecture choices and the FINN-R tool chain. The user has two different architectures available for them to choose from. A custom-tailored architecture to fit their neural network called, Dataflow Architecture (DF), and a dataflow pipeline architecture that offloads a significant proportion of the compute load and iterates over the pipeline (MO). The FINN-R tool chain has frontends, an intermediate representation and backend that takes a QNN (Quantized Neural Network) and outputs a deployment package for both the DF and MO architecture. Today FINN-R has frontends for BinaryNet, Darknet, Tensorpack and more importantly due to its modular nature, it can add support for new QNN frameworks as they emerge by adding additional frontends. The user can choose the deployment package while being sure whichever one they pick is the best hardware implementation given their design constraints.
The key difference between FINN and INT4 DPU is that FINN generates tailor-made hardware implementation for any few-bit neural networks, where weights, activations and layers can have different precisions. FINN also allows customisation of many other things such as layers and operators. This is highly valuable to optimally scale performance of a design up and down for given hard design constraints. On the other hand, the INT4 DPU accelerates model inference up to 77% compared to today’s INT8 DPU from popular deep learning frameworks and deploys them to any device across the Edge and Cloud but requires fixed hardware resources. These two flows add to the large number of choices that users can pick from to accelerate inference on Xilinx for tomorrow’s AI.
Conclusion
AI and machine learning are here to stay. Fixed architectures work well for some instances of today’s requirements. Looking forward, these models and their requirements are constantly changing, new needs are arising, and some are still not known today. Whatever it may be, Xilinx’s Adaptable Compute Acceleration Platform can meet today’s AI needs and can adapt to the evolving needs of tomorrow’s AI. Design for today, while preparing for the future of AI, with an embedded platform that can weather the changes ahead. Now let me find my Swiss Army knife so I can open a can of beans for dinner.