







At its re:Invent conference, AWS announced it next-generation AI chip called Trainium3 alongside UltraServers that enable customers to train and deploy AI models faster and cheaper.
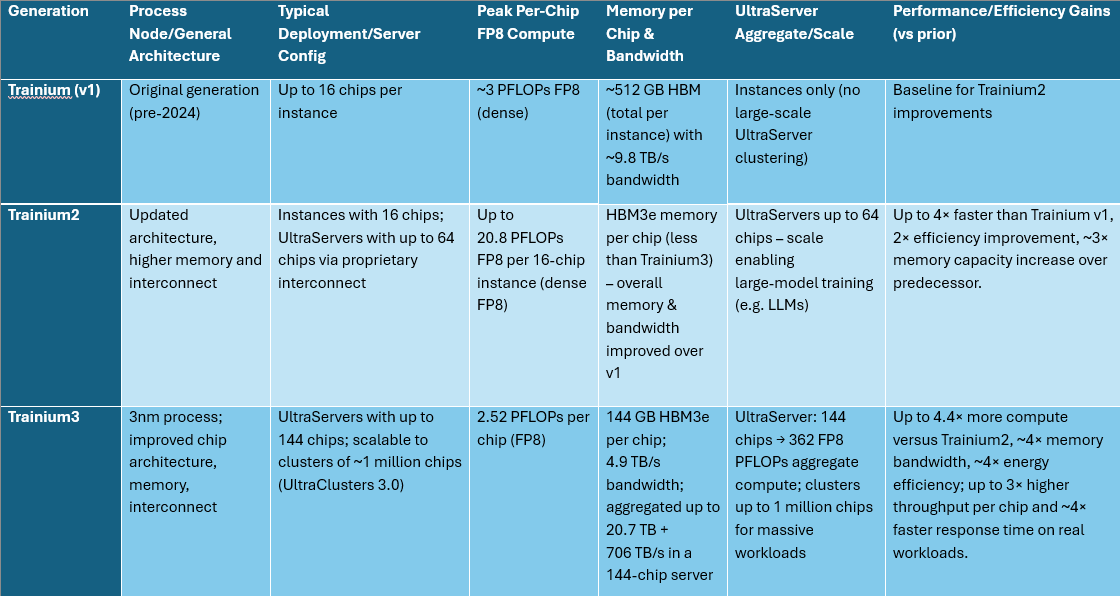
Trainium3 is AWS’ first AI chip built on a 3-nanometre process node. It combines high compute density, high-bandwidth memory, efficient power/performance characteristics, and deep software support for large scale AI training and inference workloads.
Key features:
• Each Trainium3 chip delivers 2.52 PFLOPs of FP8 compute performance
• It embeds 144GB of HBM3e memory per chip, with memory‑bandwidth of 4.9TB/s (1.7x higher than Trainium2)
• In server configuration (Trn3 UltraServer), up to 144 Trainium3 chips can be assembled – delivering aggregate 362 FP8 PFLOPs, ~20.7 TB of HBM3e, and aggregated memory‑bandwidth up to ~706 TB/s
• The new servers deliver up to 4.4x more compute performance, nearly 4x greater memory bandwidth, and over 4x energy efficiency compared to Trainium2‑based UltraServers
• On typical workloads (for example GPT‑OSS, an open‑weight LLM), customers saw ~3x higher throughput per chip and ~4x faster response times versus Trainium2
• The accompanying infrastructure includes a new interconnect fabric, NeuronSwitch‑v1, which doubles internal bandwidth per UltraServer and reduces chip‑to‑chip latency to under 10 microseconds
• Trainium3 supports a variety of precision formats (e.g. MXFP8, MXFP4, FP8, FP16, BF16), and benefits from optimisations like sparsity, micro‑scaling, and stochastic rounding
• Development tools: the AWS Neuron SDK supports Trainium3, enabling native integration with major ML frameworks (e.g. PyTorch, JAX) – so developers can migrate existing codebases without rewrites or optionally dive into low‑level optimisation via the Neuron Kernel Interface (NKI)
Trainium3 offers a significant leap for organisations looking to develop or serve large transformer-based models (LLMS), multimodal AI, reinforcement-learning, or reasoning systems.
As AI models grow in size and complexity, they are pushing the limits of compute and networking infrastructure. Trainium3’s larger memory per chip, higher interconnect and memory bandwidth, and scaling to server clusters improves training speed, reduces power consumption per unit, and enables inference at large scale with lower latency and higher throughput.
Trainium3 UltraServers
AWS also announced EC2 Trn3 UltraServers, powered by the new Trainium3 chip. Trn3 UltraServers enable organisations of all sizes to train larger AI models faster and serve more users at lower cost.
Trn3 UltraServers pack up to 144 Trainium3 chips into a single integrated system, delivering up to 4.4x more compute performance than Trainium2 UltraServers. This allows organisations to tackle AI projects that were previously impractical or too expensive by training models faster, cutting time from months to weeks, serving more inference requests from users simultaneously, and reducing both time-to-market and operational costs.
In testing Trn3 UltraServers using OpenAI’s open weight model GPT-OSS, customers can achieve 3x higher throughput per chip while delivering 4x faster response times than Trn2 UltraServers. This means businesses can scale their AI applications to handle peak demand with less infrastructure footprint, directly improving user experience while reducing the cost per inference request.
AWS engineered the Trn3 UltraServer as a vertically integrated system – from the chip architecture to the software stack. At the heart of this integration is networking infrastructure designed to eliminate the communication bottlenecks that typically limit distributed AI computing. The new NeuronSwitch-v1 delivers 2x more bandwidth within each UltraServer, while enhanced Neuron Fabric networking reduces communication delays between chips to just under 10 microseconds.
For those who need to scale, EC2 UltraClusters 3.0 can connect thousands of UltraServers containing up to 1 million Trainium chips – 10x the previous generation – giving them the infrastructure to train the next generation of foundation models.
Customers are already seeing significant value from Trainium, with companies like Anthropic, Karakuri, Metagenomics, Neto.ai, Ricoh, and Splashmusic reducing their training costs by up to 50% compared to alternatives. Amazon Bedrock, AWS’s managed service for foundation models, is already serving production workloads on Trainium3, demonstrating the chip’s readiness for enterprise-scale deployment.
Plans for Trainium4
AWS is already working on Trainium4, which is being designed to bring significant performance improvements across all dimensions, including at least 6x the processing performance (FP4), 3x the FP8 performance, and 4x more memory bandwidth to support the next generation of frontier training and inference.
To deliver even greater scale-up performance, Trainium4 is being designed to support NVIDIA NVLink Fusion high-speed chip interconnect technology. This integration enables Trainium4, Graviton, and EFA to work together seamlessly within common MGX racks, providing organisations with a cost-effective, rack-scale AI infrastructure that supports both GPU and Trainium servers. The result is a flexible, high-performance platform optimised for demanding AI model training and inference workloads.








