









With billions of dollars and an increasing percentage of the world’s energy consumption going into AI, scaling AI infrastructure efficiently – both in terms of cost and power – is a challenge requiring rethinking of system architectures.
Unclogging the ‘data pipeline’ – that path data must take between storage and processors – is of primary importance in enabling efficient scaling of AI infrastructure and efficient execution of AI processes.
The legacy bottleneck: why traditional memory and storage architectures choke AI
AI workloads – especially training and inference on GPUs – produce and consume data in small, random I/O sizes (often hundreds of bytes to a few kilobytes). That’s well aligned with memory architecture, but a disaster for storage devices, which are optimised for larger block sizes. At the same time, traditional system architectures require memory to directly attach to CPUs, limiting scalability.
- I/O mismatch increases latency and stalls GPU fetches, which blocks core compute cycles and increases energy per inference or training step. NVIDIA partner efforts point to the need for SSDs capable of 100 million IOPS to keep up with GPU memory bandwidth and prevent GPU stalls
- Memory capacity and bandwidth scale poorly: stacking more DRAM can require adding CPUs in lockstep. Not only is this costly, but it still leaves systems bound by the memory wall (the growing gap between compute capability and memory bandwidth/latency)
A recent open-access paper, ‘Future-proofing AI storage infrastructure: Managing scale, performance and data diversity’, describes how conventional monolithic storage systems are rapidly becoming insufficient to support data-intensive AI pipelines without redesign.
Intelligent storage: rebuilding the pipeline for AI and energy efficiency
To meet the scale and responsiveness required by AI workloads, the storage and memory hierarchy must evolve. Intelligent storage architectures do more than just move data – they actively optimise it across layers, reduce unnecessary movement, and align I/O with how AI models process information.
- Intelligent data tiering
Modern AI workloads exhibit highly variable access patterns. Intelligent storage solutions dynamically move data across performance tiers – HBM, DRAM, CXL, NVMe SSDs, and capacity drives – based on usage frequency, latency sensitivity, and access locality. This reduces GPU idle time and improves performance-per-watt. Incorporating machine learning into tiering logic allows systems to preemptively move hot data closer to compute or stage cold data for batch processing, minimising latency spikes and network overhead.
- The evolving memory-storage hierarchy
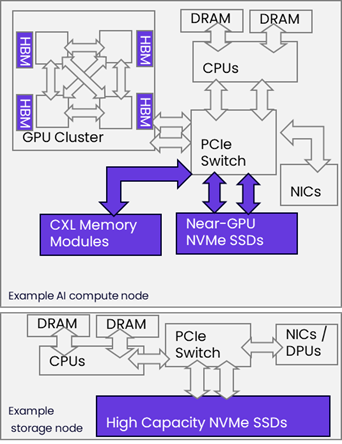
The memory-storage hierarchy traditionally spanned from small on-processor caches to DRAM, SSDs, HDDs, and Tape – with costs and performance dropping and capacities climbing by orders of magnitude at each step. Recent and upcoming technologies give AI systems an expanded span:
- HBM: new Ultra-fast, low-latency, on-package memory
- DRAM: traditional high-bandwidth system memory
- CXL Memory: a recently launched technology for shared, expandable memory pools accessed with near-DRAM latency
- Near-GPU NVMe SSDs: an emerging class of high-performance SSDs collocated with accelerators to minimise transport latency. Early enhancements include write reduction technologies. Future enhancements include redesigning SSD controllers for smaller I/O sizes
- Standard NVMe SSDs: the high-volume runners in the industry. Based on TLC NAND with capacities from 2 to 16 terabytes (TB), these are the workhorses for today’s high-performance workloads
- Capacity SSDs: cost-effective storage for large datasets with decent performance. This tier is dominated by high-density drives using QLC NAND to store 32TB or more per drive (128TB and 256TB drives have been announced). These focus on larger I/O and more sequential throughput per TB or per watt
- HDDs & Tape: long-term, low-cost archival and compliance storage. While SSDs now exceed HDDs in capacity density, HDDs and Tape retain the lowest cost per TB of storage capacity
This layered model lets architects right-size memory and storage for performance, capacity, and cost. Intelligent management across tiers – whether at the device, OS, or orchestration layer – enables AI infrastructure to scale sustainably.
- NVMe and CXL SSDs optimised for AI
Specialised SSDs for AI workloads integrate:
- Write reduction technology to lower flash wear and improve efficiency
- Compression hardware for inline data size reduction without CPU overhead
- Small I/O optimisations, such as fast metadata handling and minimal overhead for 512B-4KB reads and writes
- CXL protocol support, allowing SSDs to participate in memory-centric compute architectures, reducing CPU-GPU-SSD bottlenecks
These features are essential in handling AI’s frequent checkpointing, random access, and fine-grained read-modify-write operations.
- CXL for cost-and power-efficient memory expansion
Compute Express Link (CXL) allows memory to scale independently of CPUs, pooling capacity, and improving utilisation across nodes. It reduces the need to overprovision DRAM and supports tiered memory models that shift data across CXL-attached devices dynamically.
For AI training, CXL helps maintain performance while lowering total system cost. For inference at the edge, CXL can enable lightweight nodes to run larger models or batches without exceeding their local DRAM budgets – all with better energy proportionality.
Research like ‘SkyByte: Architecting an Efficient Memory Semantic CXL-based SSD’ explores how CXL storage and memory can converge to build composable infrastructure that matches AI workloads more precisely.
Selecting intelligent storage: what IT leaders should look for
At the time of evaluating storage options promising plug-and-play integration without full architectural redesign, here are the key criteria to assess:
- Small block I/O optimisation: ensure the SSD controller supports native compression for small random I/O, matching GPU cache and LLM fetch patterns
- CXL support and integration ease: newer CPUs compatible with CXL for memory pooling and dynamic expansion. Ideally, they should be recognised as memory by the host OS, requiring no major redesign of application logic
- Energy proportionality features: energy proportional storage adapts power usage to utilisation levels. SSDs that dynamically throttle or shut down idle lanes save energy without sacrificing responsiveness – especially critical in burst AI workloads
- Transparent ECC and capacity scaling: modules that integrate ECC and support higher capacity at lower cost (via DRAM + CXL combos) reduce the need for overprovisioned DRAM banks, improving performance per dollar and watt
- Minimal host software changes: prefer devices that expose themselves as standard NVMe or memory modules, avoiding kernel patches, proprietary drivers, or overhauling the existing stack
Why this matters now: energy, Edge, and enterprise impact
- Energy efficiency is no longer optional: IEA reports forecast that electricity infrastructure – not compute – may become the critical bottleneck as AI scales globally
- Enterprise sustainability initiatives increasingly demand performance-per-watt optimisation across all layers of infrastructure
- Edge AI deployments require compact, efficient storage and memory stacks that reduce latency and power draw while still handling sophisticated models, enabling inference close to data sources
By adopting intelligent storage, organisations can reduce latency, keep GPUs saturated, cut energy use, and scale both capacity and compute gracefully.
Conclusion: redesigning storage, unlocking AI efficiency
What began as a GPU-idle experiment underscores a broader truth: traditional storage systems are now a critical performance and energy bottleneck in AI workloads. Legacy SSDs and DRAM pipelines often fail to match the scale, I/O patterns, and energy goals of modern systems.
Intelligent storage – combining intelligent data tiering, inline hardware compression, CXL memory expansion, and energy-proportional design – offers a path to unlock AI performance at scale with better efficiency. When evaluating new storage solutions, focus on I/O alignment with AI workloads, integrated compute offload, CXL support, and plug-and-play integration.
With these innovations, system designers and technology leaders can bridge the memory wall, reduce energy footprints, and enable high-performance AI across cloud, Edge, and hybrid environments – without costly architectural overhauls.
About the author:

JB Baker, the Vice President of Products at ScaleFlux, is a successful technology business leader with a 20+ year track record of driving top and bottom-line growth through new products for enterprise and data centre storage. After gaining extensive experience in enterprise data storage and Flash technologies with Intel, LSI, and Seagate, he joined ScaleFlux in 2018 to lead Product Planning & Marketing as the company innovates efficiencies for the data pipeline. He earned his BA from Harvard and his MBA from Cornell’s Johnson School.









