
Securing & simplifying IoT application development
The 21st century is witnessing significant change; devices are becoming smarter by connecting to the Internet, supporting intelligent interaction and rational decision-making. While modern life becomes more dependent on devices, have we reached a point where they need each other more than they need us?
For a device to be ‘smart’ it needs a ‘brain’ that can recall previous ‘experiences’. Moreover, this brain must be resilient enough to recover from any kind of failure. When it comes to devices, this brain is called a database. Although cloud storage can serve as a repository for all devices' collective knowledge and experience, an individual device should not be left without an internal brain to fall back on in cases such as power failure or lost connectivity. Therefore, as we move forward in the Internet of Things era, embedded database becomes an important development tool that should be employed from the conception of a new device.
Many devices, such as those used for mobile inventory management, will communicate with a large back-end database server to manipulate a subset of its data. An embedded database on the device is the best tool to save data reliably in a format that is easily shared with the back-end server. In addition, an embedded database that understands the data's structure can automatically perform the necessary conversions when a database is shared between devices, either by copying the database file itself or using network communications to synchronise the database.
For developers of embedded systems and intelligent devices, storing, organising and sharing data makes up a large part of the memory requirements for an application. An embedded database library is a useful development tool to manage memory more effectively, by both imposing bounds on memory usage and analysing worst-case behaviour in a consistent way. The database library can handle all the details of reading, writing, indexing and locking data within a predictable footprint, so that the application's own memory requirements are greatly reduced.
The database can be embedded directly in the application, completely hidden from the end-user and greatly simplifying management and maintenance. Developers can choose an embedded database with a code footprint of less than a megabyte, that can be customised to satisfy strict footprint requirements and fit easily on an embedded device. Such an embedded database should use algorithms that are efficient for small-scale applications, but that easily scale to store a large amount of data.
An embedded database can also store data in a portable format to be accessed directly either using table cursors, or with SQL queries. It should provide features such as shared access and even allow the SQL engine to be omitted to reduce footprint. An application's storage requirements often change over time, requiring updates to the database schema. A database can support dynamic schema alteration, allowing applications to add and remove tables and columns to a live database. At the same time, the database can use a buffer pool to control memory usage and prevent fragmentation for best performance and minimal wear on storage: this accountability for memory utilisation is critical in embedded systems.
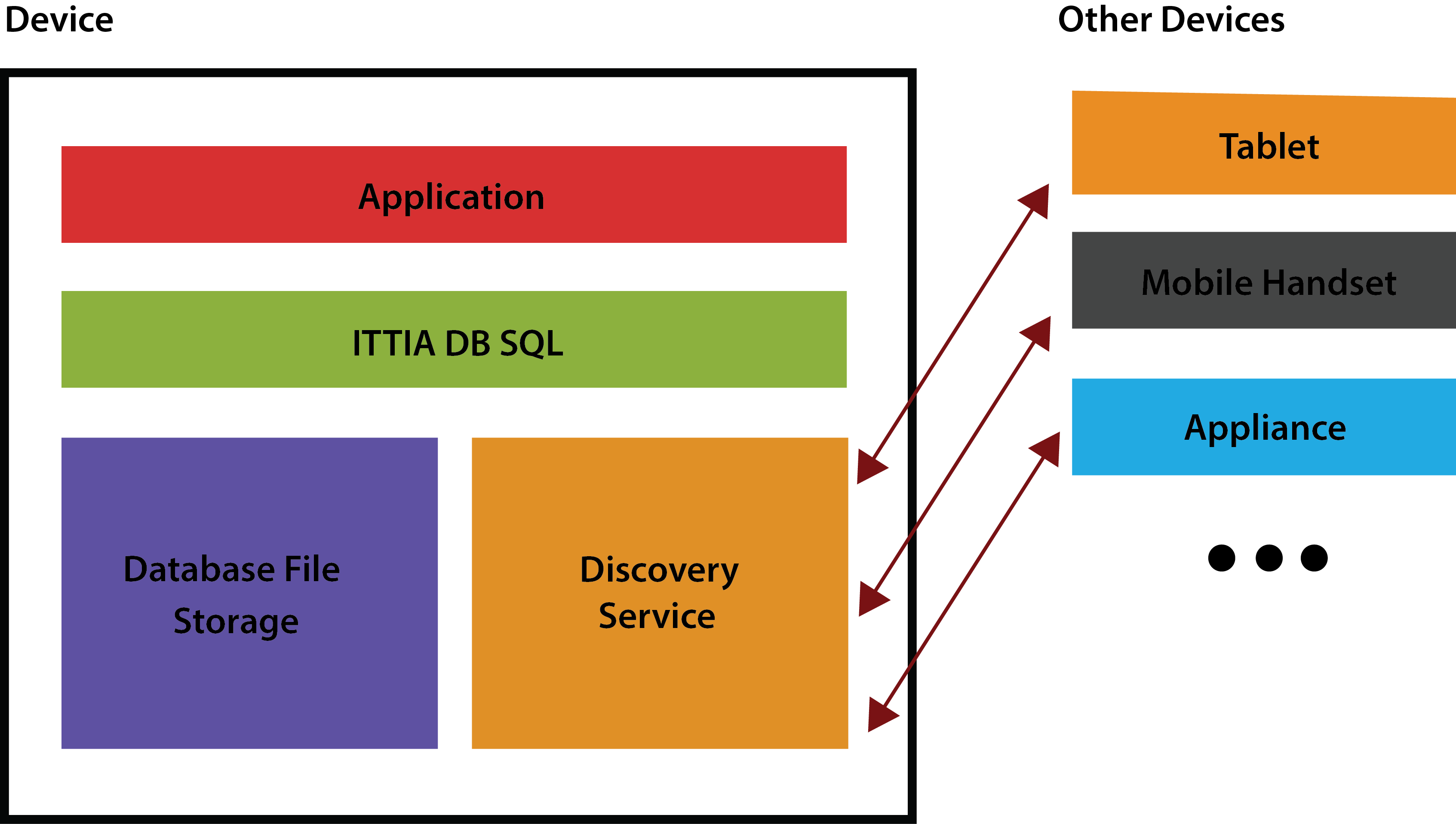
Figure 1 - Clients can connect to a server on the same device using an efficient shared memory protocol, or TCP/IP networking
When needed, smart applications can share access to the database by opening a separate connection for each task. Within a single process, each connection is able to access the database file directly, while multiple processes can share a database file by connecting to a server process through shared memory or TCP/IP. In such cases, regardless of how many connections there are or how they are made, each database file uses only one page cache.
A database can use either storage-level locking, or a less restrictive locking technique known as row-level locking with isolation levels. In this case, the database automatically tracks all rows that are read or modified in a transaction. At the highest level of isolation, known as ‘serialisable’, rows are locked in such a way as to prevent all possible conflicts. And for most simple transactions, the isolation level can be reduced to minimise locking even further, to ensure that a transaction is only blocked when it would create a conflict with another transaction already in progress. In addition, an entire table can be locked manually.
Leveraging SQL
ITTIA DB SQL is a lightweight relational database library that is designed for embedded systems and mobile devices. It supports automatic recovery, transactions, indexes, and shared access. It can be deployed as a stand-alone library that requires no administration. Alternatively, ITTIA DB SQL supports client/server access that enables sophisticated data sharing with row-level locking, in order to simplify development and minimise footprint on embedded systems.
Both ad-hoc SQL and direct table access are supported by ITTIA DB-SQL. C++ software developers can take advantage of the C++ API, or use the low-level C API. The ITTIA DB SQL C API binds database rows directly to memory addresses controlled by the application, to minimise data copying when queries are executed.
Data is stored in a platform-independent format that is transferable to any supported operating system and processor architecture. This allows data to be easily migrated from one device to another and greatly helps in development when the host and target architectures are different.
Data sharing and distribution is a modern trend in data management for smart devices. With the rise of intelligent-connected devices, anyone can own a general-purpose smart device that is capable of storing and sharing large amounts of data with other smart devices nearby. In a typical smart environment where data needs to be distributed, data is duplicated across multiple sites, each running independently. Distributed data access provides individuals with greater freedom over where and when they can access the system, especially when mobile devices are used. Reliability is increased as well, because data is effectively backed up when redundant copies are made, protecting it from media failure and other physical damage to any one device.
Product Spotlight
APV1111GVY
Panasonic

Panasonic PhotoMOS® Photovoltaic MOSFET High-Power Drivers
| SKU: | |
|---|---|
| Stock: | 3490 |
| Cost: | $3.95 |
