
Big data for everyone
Collecting and analysing measurement data throughout a company is an important requirement for continuous product optimisation. By using intelligent open source solutions, now even large amounts of data can be saved at a low cost and be evaluated with the help of big data technologies. Dr. Hans-Jörg Kremer, Peak Solution explains.
Technical departments that test electronic or mechanical components, modules or entire vehicles usually document their results locally. Due to the resulting isolated solutions however, measurement data is rarely used outside their origination process. Nonetheless, measurement data is valuable because they represent knowledge about products and their development. A measurement data management system that is used in combination with big data technologies enables the long term systematic use of measurement data and extrapolates them for the entire life span of the product.
Since individual vehicle components are often used unchanged in the succeeding models, even older test results can become relevant again. Well researchable data storage, as well as processes with which patterns and coherences are recognised across tests, projects, departments and locations therefore offer decisive competitive advantages. Moreover, in order to allege performed tests in case of a product liability litigation in the automotive industry, data often has to be stored for up to 30 years. There seems to be a general agreement on keeping measurement data and test documentation available over the entire life span of a product.
On the limit
Measurements are, however, accumulated in enormous amounts that increasingly go beyond what can be saved in an economically viable way on traditional file servers. In some fields, such as driver assistance systems, several terabytes of data are accumulated per week. Those who point out the intrinsic value of measurement data and want to keep everything are put in their place by economical sense time and time again.
In view of the petabytes of data that are stored, “we may still need that” sounds like an argument put forward by a measurement data hoarder who has to be forced to select important data. However, gigantic amounts of data is not a problem specific to test bench operators. Today, under the term big data, various methods for storing and evaluating large amounts of data are used with great success in other fields. Even massive volumes of measurement data can be processed with it.
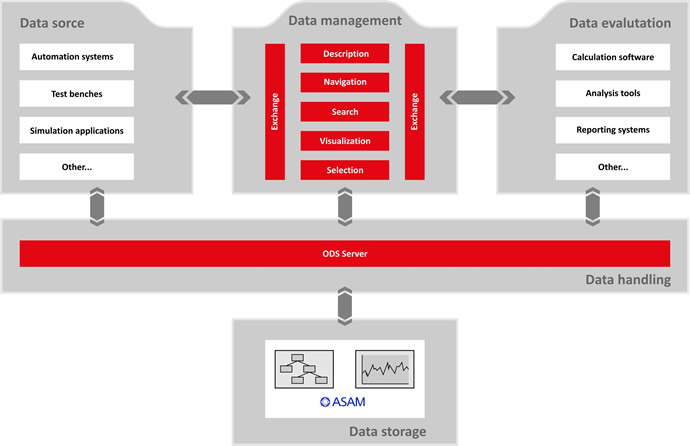
When introducing a company wide measurement data management system, the proprietary formats in which the data of measuring devices and test benches are saved are a challenge. In order to interpret and compare the measured data correctly every time, they have to be documented with descriptive information. This metadata is used to evaluate the professional, organisational and technical context of measurements. Part of this context is, for example, the exact description of the specimen, the measuring equipment used, the test sequence as well as organisational and job oriented data. With this information, it is later possible to navigate the database and conduct specific searches.
ODS (Open Data Service) by ASAM e.V. (Association for Standardisation of Automation and Measuring Systems) is a standard that has proven successful as a basis for this kind of test data storage for more than a decade. The standard is used by a large number of renowned companies throughout the world.
Future-proof solutions
Today, with the help of suitable software platforms, ODS-based solutions can be implemented in an economical and future-proof way. The openMDM open source software system is such a platform. The origins of openMDM lie in a measurement data management system by Audi. Since 2008 it has been further developed into a versatile and scalable enterprise solution by an open community consisting of about 30 vehicle manufacturers, suppliers and service providers. With the establishment of the openMDM Eclipse Working Group (www.openmdm.org) a new organisational framework was created in 2014, with which it is possible to promote the further development and international distribution of openMDM more intensively. The driving forces behind this are, among others, Audi, BMW and Daimler. M.
The software components of openMDM help users with the individual steps of the test procedure and therefore enable standardised or automated recurring work sequences. The process support covers everything from test description and commissioning to test data storage, navigation, search and selection. Measurement systems and analysis tools from different manufacturers can be integrated into the process flexibly with open interfaces.
This way, it is possible to import the measurement data from different test systems without much development effort and to save and manage them together with their descriptive information (metadata) in compliance with ASAM ODS. By navigating or searching the database, the data in openMDM can be found, compiled and then forwarded to different analysis tools for further processing.
This way, companies are able to standardise and design their test processes in the different specialist fields independently from the vendor. This brings about a transition from proprietary, local solutions to truly integrated working environments with the best tools at hand. That means that with this open, vendor independent approach by openMDM, it is possible to use the tools (i.e. measurement systems, analysis tools, evaluation programmes, etc.) of different manufacturers that have proved to be most suitable for certain tasks or steps in the test process of a specific specialist field. In spite of the different systems, the result is a comprehensive and consistent overview of all test data in each specialist field.
Enough storage for results
However, the amount of test data in the specialist fields and their diversity in terms of kind (e.g. structured, not structured, partly structured) and format (proprietary, standardised, video, audio, graphic, XML, text, office etc.) are increasing steadily. In order to store this data for subsequent evaluation, Peak Solution suggests to store them on commodity hardware.
Here, a freely available solution is chosen as well. The open source project Hadoop by Apache Software Foundation enables the distributed storage and processing of large amounts of data in horizontally distributed environments. One core component of Hadoop is HDFS (Hadoop Distributed File System). It is a large distributed file system with which the fault tolerant distribution of large amounts of data to several thousand servers within a cluster is possible (‘scale out’).
The special feature of this system is that it does not require any special, expensive servers, but can be used with any hardware. Hadoop Distributed File System is therefore about 20 times more cost effective per terabyte than a storage area network or analytic database (such as Enterprise Data Warehouse). There are no license fees and it is not necessary to bind oneself to one manufacturer. HDFS manages all data (i.e. the division, distribution and replication to the cluster knot) automatically. For the user, access to HDFS is similar to that of a virtual file system.
Standardised methods
The combination of openMDM and a Hadoop cluster works as follows - when importing with a domain specific openMDM system, the measurement data from the different test systems is converted to the standardised ODS file format and linked to the descriptive information (metadata). An interface such as the Peak ODS Server by Peak Solution saves both the ODS files as well as the proprietary original formats in HDFS. The server ensures that data that is created and/or needed by different test benches, measuring equipment, simulation systems, analysis tools and evaluation programmes, are stored and/or loaded in an ODS compliant way. It can be data such as metadata (e.g. test or simulation orders, test descriptions or calibration information), measurement data (e.g. individually measured values, image, video and audio files or actual data from the performed tests) as well as result data (e.g. evaluation and calculation results).
Regardless of the data’s source and format, the Peak ODS server ensures that the different applications have access to it via standardised interfaces and methods. By enclosing interfaces, the specific type of data storage no longer plays a role for the respective client application. That means that all ODS compatible data acquisition, automation, simulation or analysis systems can store and load configuration and result data in compliance with ODS.
With this approach, data that has been deleted due to a lack of storage space before can now also be kept. Metadata is stored in the relational database of the openMDM application. The free Software Apache Lucene continuously creates an index. This index and the Lucene search engine technology, which is used with Wikipedia for example, now enables what was requested at the beginning - a company wide measurement data management system. With explorative and iterative browsing, as well as text mining, the search engine makes it possible to find tests with specific attributes in the entire database across applications and departments. If the user has the corresponding access authorisation, he can use the test data he found, even those from other test departments, for comparisons and analyses of his own.
Analysis options
Beside a cost efficient storage space for measurement data, the HDFS cluster now also offers various evaluation options, which are usually grouped under the term big data analytics. Data from different applications and specialist fields can be put in relation with each other and new correlations can be derived from them. If, for example, someone develops simulations for SiL and HiL tests for components of a driver assistance system, he could obtain valuable information from the analysis of data from driver tests.
Semantic networks can be shaped with graph-based methods in order to recognise more than just the obvious relations and dependencies between different data objects of the test environment. Based on this information, it is possible to create modern note and recommendation systems as well as knowledge databases for test engineers. The expertise of individual departments becomes collected knowledge about the entire testing process within the company and beyond.
The big data approach makes it possible to search for global correlations. For instance, for driver tests that are performed all around the world under the most different conditions, the communications can be recorded on the data bus of the different test vehicles.
In parallel, sensors are used to collect a large amount of information about individual vehicle components (e.g. engine, gear, brakes, etc.) and by using video measuring equipment, street and environment information can be collected. With this information, comprehensive analyses about the behaviour of certain vehicle types in defined situations can be conducted. These analyses may provide leads to how the interaction of individual vehicle components can be optimised. In a broader sense, the knowledge gained from measurement data can be for further product development.
The idea behind big data has only just arrived in the area of measurement data management. It is not clear yet which questions can be answered by the masses of data and which analyses possibilities are provided. Thanks to the interaction of openMDM with Hadoop and Lucene, company-wide measurement data management using large databases is made possible on the basis of specific openMDM installations in the different specialist fields from engine manufacturing and chassis to vehicle assistance and entertainment.
This is an important aspect because the preliminary work of external development partners and platform developments across companies is rather likely to increase. With the ‘generous’ data collection in the HDFS cluster, marginal data that up until now has been deleted can now be evaluated in their origination contexts even if they were created by the service providers. OEMs that use the big data principle therefore gain another piece of comprehensive knowledge about the lifecycle of their products and sub-systems beyond an individual, final audit report.
Product Spotlight
APV1111GVY
Panasonic

Panasonic PhotoMOS® Photovoltaic MOSFET High-Power Drivers
| SKU: | |
|---|---|
| Stock: | 3490 |
| Cost: | $3.95 |
