
Devices that treat the patient must protect the patient
The US Food and Drug Administration (FDA) has long mandated the use of quality systems to ensure that medical devices are safe and effective for their intended purpose for both the patient and the operator of the device. As Jay Thomas of LDRA Technology highlights, that safety and effectiveness also relies on security in the increasingly connected medical environment.
Today’s medical devices must not only comply with FDA requirements for safety and effectiveness, it is also imperative that they be secure from unauthorised access and hacking, both for patient and operator safety as well as privacy, as mandated by laws such as HIPAA. If the devices are not secure, they cannot be considered safe or reliable. Thus the requirements for safety, reliability and security are inseparable and interdependent, and must be designed-in from the ground up, not as an afterthought.
Implementing security involves a number of aggregating strategies including the use of secure booting and firmware upgrades, encryption, password protection, recognition technologies and device, firmware and software authentication. Secure transfer protocols such as transport layer security (TSL), which is an improvement over the secure sockets layer (SSL), and the secure file transfer protocol (SFTP) are now widely used but are often acquired from outside the organisation. However, using these (by either importing them or writing them from scratch) can also introduce flaws that result in security vulnerabilities. This raises new concerns around software of unknown pedigree (SOUP). In fact the FDA has published a set of guidelines for hazard analysis and mitigation in off-the-shelf software, which can be of value for evaluating SOUP code. Even code that is considered safe and reliable, especially if it is third party code, must be suspect.
Of course, software for medical devices should follow recognised standards such as IEC 62304, which is now seen as the industry best practice for the development of medical device software. The standard establishes a framework of software development lifecycle processes with activities and tasks necessary for the safe design, development and maintenance of medical device software. In addition, the FDA has recently issued guidelines for implementing cyber security in medical devices that will lead to further requirements for compliance. The new FDA guidelines require that manufacturers address issues of cyber security from the product development stage to post-market management.
However, the ability to comply with the complexity of various guidelines and requirements requires the use of adequate tools, which also aid in documenting standards compliance for device approval. Today’s comprehensive tool suites integrate testing, analysis and verification in a single development environment. The FDA guidelines also place a great deal of emphasis on process - from requirements to code coverage to unit/integration testing and more (Figure 1). The use of a comprehensive tool environment can also help establish a disciplined methodology within an organisation that can help teams cooperate even though they may be working in different locations. For example, the adoption of a coding standard can be traced and verified with static analysis tools to assure a uniform coding methodology throughout the operation.
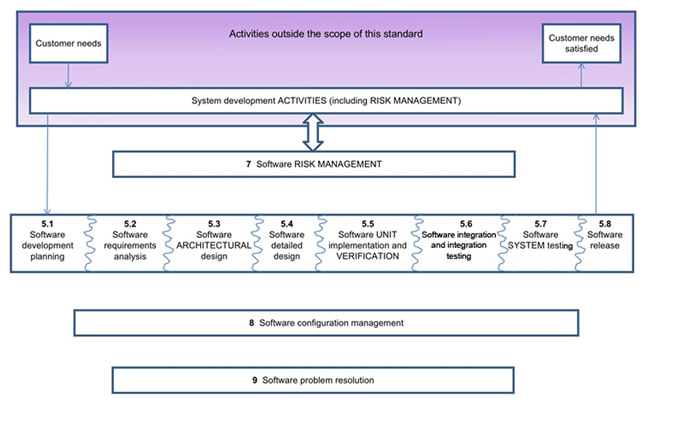
Figure 1: Overview of software development processes and activities. Note particularly the process and lifecycle stages 5.1 through 5.8
In terms of cyber security, the FDA guidelines are based on the existing ‘Framework for Improving Critical Infrastructure Cybersecurity’ published by the National Institute of Standards and Technology (NIST). Together the guidelines form a risk-based approach to implementing secure systems. Tools help define and guide developers so they can prove that they properly followed the process and produced the appropriate artifacts.
Proper use of software tools can also help ensure that high assurance safe and secure coding practices were followed. The task of the developer of secure medical devices is to produce high quality software that is traceable from security requirements through to deployment and maintenance.
Verifying security requirements with traceability and analysis
Three major capabilities under the supervision of two-way requirements traceability are applied early on and at successive stages of the development process. These are static analysis, dynamic analysis for functional test and structural coverage analysis, and unit testing/integration testing. The latter applies both static and dynamic analysis early in the development process and is also applied to the later integrated code (Figure 2). In addition, it is advisable to adopt a coding standard even though no particular standard is required in the FDA guidelines, nor under IEC 62304. A good choice would be MISRA C, which has recently been enhanced with a set of security guidelines in addition to its general coding rules.
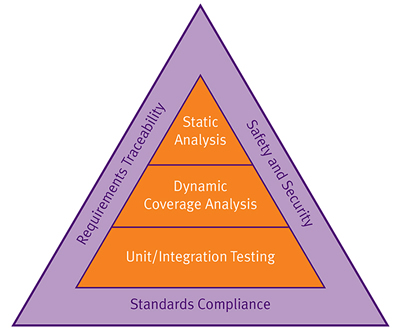
Figure 2: The three solid blocks of code quality - static analysis, dynamic analysis, and unit testing and integration - serve the goals of safety and security, standards compliance and requirements traceability to offer a fully verified and even certifiable software system.
In order to meet qualification or certification requirements, tools that allow bi-directional requirements traceability - from requirements to design, to implementation and verification activities and artifacts - can differentiate an organisation from the competition and ensure the shortest path to device approval. Requirements traceability and management increases code quality and the overall safety, security and effectiveness of the application. A requirements traceability tool lets teams work on individual activities and link code and verification artifacts back to higher level objectives.
Bi-directional traceability, from function, safety and security requirements, all the way down to and through the code to the verification activities and artifacts is needed to ensure that every high level and low level requirement is properly implemented and tested. Likewise, each piece of code and the corresponding verification activities and artifacts should be clearly traceable back to their originating requirements. This level of transparency is required in domains where safety and security are the most critical goals.
Static and dynamic analysis: Partners in security
In assuring security, the two main concerns are data and control. Questions that must be considered include: Who has access to what data? Who can read from it and who can write to it? What is the flow of data to and from what entities and how does access affect control?” Here the ‘who’ can refer to people like developers and operators (and hackers) and it can also refer to software components, either within the application or residing somewhere in a networked architecture. To address these issues, static and dynamic analysis must go hand in hand.
On the static analysis side, the tools work with the uncompiled source code to check the code for quality metrics such as clarity, consistency and maintainability. In addition, static analysis can be used to check the code against selected coding rules, which can be derived from any combination of the supported standards such as MISRA or CERT as well as any custom rules and requirements that the developer or a company may specify. The tools look for software constructs that can compromise security as well as to check memory protection to determine who has access to which memory and to trace pointers that may traverse a memory location. Results should ideally be presented in graphical screen displays for easy assessment to assure high quality code as well as coding standards compliance (Figure 3).
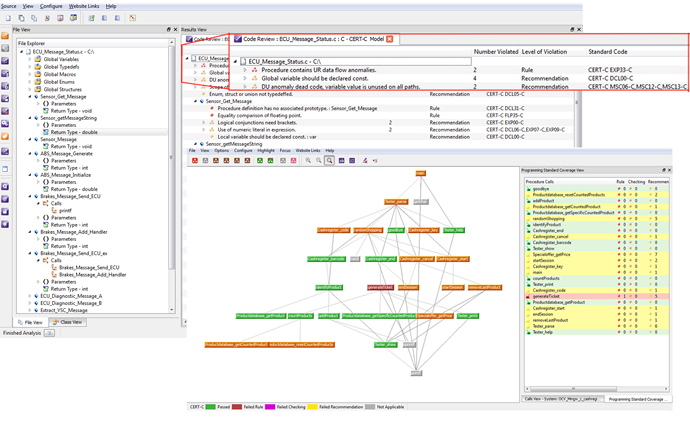
Figure 3: In the LDRA tool suite, coding standards compliance is displayed in line with the file/function name to show which aspects of the system do not comply with the standard. The programming standards call graph shows a high level, colour coded view of coding standards compliance of the system.
On the other hand, dynamic analysis operates on the compiled code, which is linked back to the source code automatically. Dynamic analysis, especially code coverage analysis, provides extensive testing and visualisation of the run time dynamics, explicitly identifying code that has and has not been executed as a result of the test vectors injected into the system. Often developers manually generate and manage their own test cases. This is the historical and typical method of generating test cases - working from the requirements document. They may stimulate and monitor sections of the application with varying degrees of effectiveness. However, given the size and complexity of today’s code, that will not be enough to achieve certain required testing effectiveness (Figure 4).
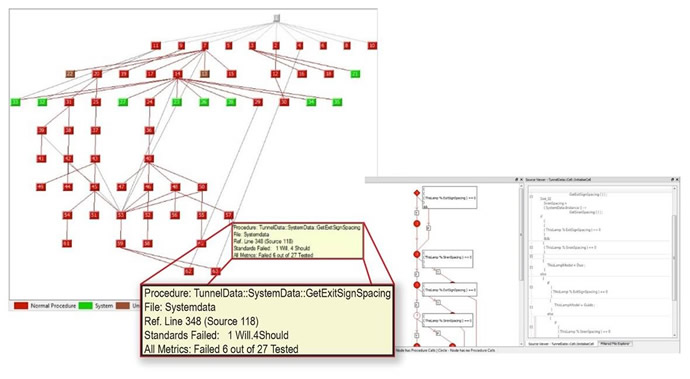 Figure 4: Reports of variable and parameter usage are based on the current test run. The report generated by the LDRA tool suite highlights the file and location within the file where the variable was used, with custom filters that allow more refined testing.
Figure 4: Reports of variable and parameter usage are based on the current test run. The report generated by the LDRA tool suite highlights the file and location within the file where the variable was used, with custom filters that allow more refined testing.
Automatic test generation and test harness generation saves time and money and improves the effectiveness of the testing process. Automatic test case and test harness generation are based on the static analysis of the code i.e., before compilation. The information provided by static analysis helps the automatic test generator create the proper stimuli to the software components in the application during dynamic analysis.
As mentioned previously, functional tests can be created manually to augment the tests that have been generated automatically, therefore further increasing the effectiveness of the testing process. Testing should include any functional security tests such as simulated attempts to access control of a device or feed it with incorrect data that would change its mission. In addition, functional testing based on created tests should include robustness, such as testing for results of unallowed inputs and anomalous conditions.
Tools should be applied to enforce compliance with coding standards and indicate software flaws that might otherwise pass through the standard build and test process to become latent problems. For example, there is danger associated with areas of ‘dead’ code that could be activated by a hacker or obscure events in the system for malicious purposes. Although it is ideal to start implementing security from the ground up, most projects include pre-existing code or SOUP that may not have been subjected to the same rigorous testing as the current project. With the amount of SOUP available with what looks like just the needed functionality, it can be tempting to pull it into the current project. Best practices suggest that SOUP should be subjected to exactly the same rigorous analysis used in the current project. Even if it is correctly written, such code may contain segments that are simply not needed by the application under development. Used together, static and dynamic analysis can reveal areas of dead code, which can be a source of danger or may just inconveniently take up space. It is necessary to properly identify such code and deal with it - usually by eliminating it.
The ability to distinguish between truly dead code and seldom-used code is yet another reason why bi-directional requirements traceability is important - to be able to check that requirements are met by code in the application, but also to trace code back to actual requirements from the actual code. If neither of those routes shows a connection, the code definitely does not belong there.
Because medical devices come in all ranges of size, complexity and levels of criticality, the FDA has designated three distinct risk classes based on their criticality as follows:
- Class A: No injury or damage to health is possible
- Class B: Non-serious injury is possible
- Class C: Death or serious injury is possible
For safety critical devices, it may be necessary to verify code at the object level. Object Code Verification (OCV) has features to implement and apply test cases that ensure full assembly level code coverage. This facility is often a requirement of safety critical development environments where it is used to complement modified condition/decision coverage (MC/DC) and to support activities such as mapping source code to object code.
These capabilities allow the complete analysis of complex logical conditions and the identification of ‘compiler-added’ code. The inherent one-to-one relationship between statements in the compiler generated, intermediate assembler source code and subsequent object code means that an approach that validates the relationship between the application source code and this assembler code may be used to satisfy this OCV requirement. This approach is being used in industries with the most stringent certification requirements to ensure device safety.
Verification starts with unit testing
As units are developed, tested, modified and retested by teams of developers (possibly in entirely different locations) the test records generated from a comprehensive tool suite can be stored, shared and used as units that are integrated into the larger project. This is important from the start because thinking about and developing for security from the ground up doesn’t help much unless you can also test from the ground up - and that includes testing on a host development system before target hardware is available. At this stage, nobody is talking about the project nearing completion, so it must be possible to do early unit testing and then integration testing as assignments come together from different teams or developers.
This also applies to parts of code that may be written either from scratch, brought in from other projects, purchased as commercial products or obtained as open source. Even in-house code needs to be checked because it may not have been originally subjected to the same analysis or there may be some internal segments that need to be eliminated, modified or added. For example, it may be necessary to change the names of certain variables to comply with those used in the larger project. All these are possible avenues for introducing errors. The decision to use unit test tools comes down to a commercial decision. The later a defect is found in the product development, the more costly it is to fix.
For systems to be safe, they must also be secure
Medical devices must be coded to comply not only with language rules but also to adhere to the standards that assure safety and security. This must all be verifiable, which means the ability to trace the flow of data and control from requirements to code and back again.
Applying a comprehensive suite of test and analysis tools to the development process of an organisation greatly improves the thoroughness and accuracy of security measures to protect vital systems. It also smooths what can often be a painful effort for teams to work together for common goals and to have confidence in their final product. That product will also stand a much better chance for approval by the proper authorities.
Product Spotlight
APV1111GVY
Panasonic

Panasonic PhotoMOS® Photovoltaic MOSFET High-Power Drivers
| SKU: | |
|---|---|
| Stock: | 3490 |
| Cost: | $3.95 |
