
Opening doors with OpenCL Standard
This article from ES Design magazine introduces the OpenCL standard and explains how to implement it on an FPGA. By Deshanand Singh, Supervising Principal Engineer, Software and IP Engineering, at Altera.
As multicore processing devices first came on to the market it was recognised that there needed to be a standard model for creating programs that will execute across multiple cores and potentially different devices. The lack of a standard that is portable across different programmable technologies had plagued programmers. It was with some relief that in late 2008 Apple submitted a proposal for an OpenCL (Open Computing Language) draft specification to The Khronos Group in an effort to create a cross-platform parallel programming standard. The Khronos Group consists of a consortium of industry members such as Apple, IBM, Intel, AMD, NVIDIA, Altera, and many others. This group has been responsible for defining all the OpenCL specifications, the most current being Version 1.2.
The OpenCL standard allows for the implementation of parallel algorithms that can be ported from platform to platform with minimal recoding. The language is based on the C programming language and contains extensions that allow for the provision of parallelism.
In addition to providing a portable model, the OpenCL standard inherently offers the ability to describe parallel algorithms to be implemented on FPGAs, at a much higher level of abstraction than hardware description languages (HDLs) such as VHDL or Verilog. Although many high-level synthesis tools exist for gaining this higher level of abstraction, they have all suffered from the same fundamental problem. These tools would attempt to take in a sequential C program and produce a parallel HDL implementation. The difficulty was not so much in the creation of an HDL implementation, but rather in the extraction of thread-level parallelism that would allow the FPGA implementation to achieve high performance. With FPGAs being on the furthest extreme of the parallel spectrum, any failure to extract maximum parallelism is more crippling than on other devices. The OpenCL standard solves many of these problems by allowing the programmer to explicitly specify and control parallelism. The OpenCL standard better matches the highly parallel nature of FPGAs than do sequential programs described in C alone.
OpenCL applications consist of two parts. The OpenCL host program is a software routine written in standard C/C++ that runs on any sort of microprocessor. That processor may be, for example, an embedded soft processor in an FPGA, a hard ARM processor, or an external x86 processor, as depicted in Figure 1.
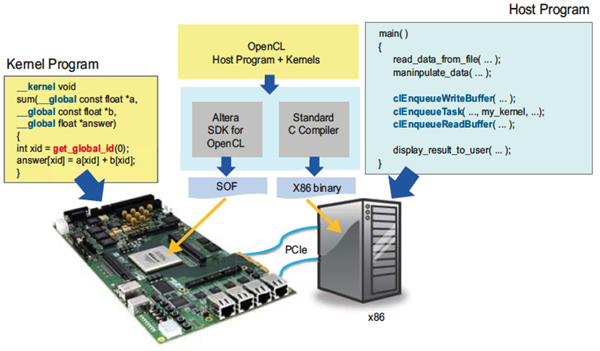
Figure 1: Overview of OpenCL
At a certain point during the execution of this host software routine, there is likely to be a function that is computationally expensive and can benefit from the highly parallel acceleration on a more parallel device: a CPU, GPU, FPGA, etc. This function to be accelerated is referred to as an OpenCL kernel. These kernels are written in standard C, however they are annotated with constructs to specify parallelism and memory hierarchy. The example shown in Figure 2 performs the vector addition of two arrays, A and B, while writing the results back to an output array answer. Parallel threads operate on each element of the vector, allowing the result to be computed much more quickly when it is accelerated by a device that offers massive amounts of fine-grained parallelism, such as an FPGA. The host program has access to standard OpenCL application programming interfaces (APIs) that allow data to be transferred to the FPGA, invoking the kernel on the FPGA and transferring the resulting data back.
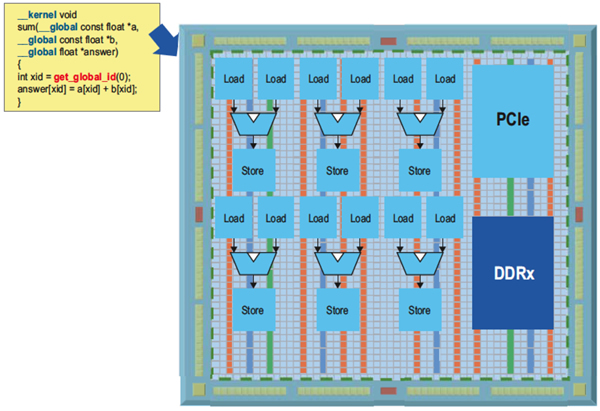
Figure 2: Example of OpenCL on an FPGA
Unlike CPUs and GPUs, where parallel threads can be executed on different cores, FPGAs offer a different strategy. Kernel functions can be transformed into dedicated and deeply pipelined hardware circuits that are inherently multithreaded using the concept of pipeline parallelism. Each of these pipelines can be replicated many times to provide even more parallelism than is possible with a single pipeline. For example, Altera’s OpenCL Compiler translates an OpenCL kernel to hardware by creating a circuit that implements each operation. These circuits are wired together to mimic the flow of data in the kernel. In our vector addition example, the translation to hardware will result in a simple feed-forward pipeline. The loads from arrays A and B are converted into load units, which are small circuits responsible for issuing addresses to external memory and processing the returned data. The two returned values are fed directly into an adder unit responsible for calculating the floating-point addition of these two values. Finally, the result of the adder is wired directly to a store unit that writes the sum back to external memory.
The most important concept behind the OpenCL-to-FPGA compiler is the notion of pipeline parallelism. For simplicity, assume the compiler has created three pipeline stages for the kernel, as shown in Figure 3. On the first clock cycle, thread 0 is clocked into the two load units. This indicates that they should begin fetching the first elements of data from arrays A and B. On the second clock cycle, thread 1 is clocked in at the same time that thread 0 has completed its read from memory and stored the results in the registers following the load units. On cycle 3, thread 2 is clocked in, thread 1 captures its returned data, and thread 0 stores the sum of the two values that it loaded. It is evident that in the steady state, all parts of the pipeline are active, with each stage processing a different thread.
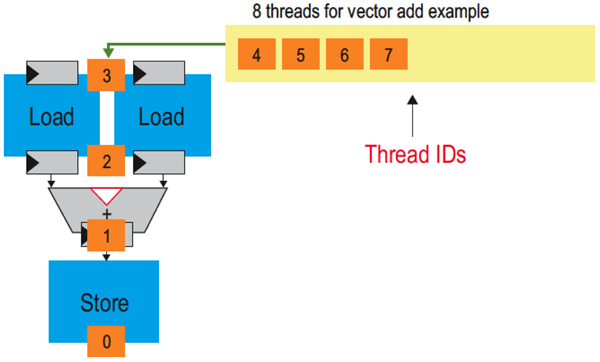
Figure 3: Pipelined information
Figure 4 shows a high level representation of a complete OpenCL system containing multiple kernel pipelines and circuitry connecting these pipelines to off-chip data interfaces. In addition to the kernel pipeline, Altera’s OpenCL compiler creates interfaces to external and internal memory. The load and store units for each pipeline are connected to external memory via a global interconnect structure that arbitrates multiple requests to a group of DDR DIMMs. Similarly, OpenCL local memory accesses are connected through a specialised interconnect structure to on-chip M9K RAMs. These specialised interconnect structures are designed to ensure high operating frequency and efficient organisation of requests to memory.
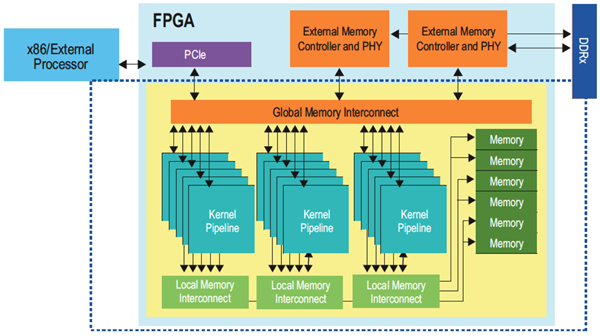
Figure 4: OpenCL system implementation
The creation of designs for FPGAs using an OpenCL description offers several advantages in comparison to traditional methodologies based on HDL design, the most significant of these is shown in Figure 5. Development for software-programmable devices typically follows the flow of conceiving an idea, coding the algorithm in a high-level language such as C, and then using an automatic compiler to create the instruction stream.
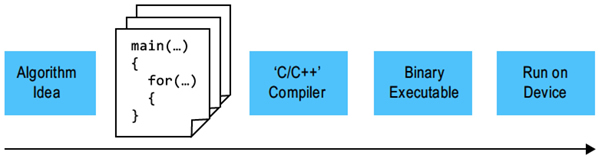
Figure 5: Programmer’s view
This approach can be contrasted with traditional FPGA-based design methodologies. Here, much of the burden is placed on the designer to create cycle-by-cycle descriptions of hardware that are used to implement their algorithm. The traditional flow involves the creation of datapaths, state machines to control those datapaths, connecting to low-level IP cores using system level tools (e.g., SOPC Builder, Platform Studio), and handling the timing closure problems since external interfaces impose fixed constraints that must be met.
The goal of an OpenCL compiler is to perform all of the above steps automatically for designers, allowing them to focus on defining their algorithm rather than focusing on the tedious details of hardware design. Designing in this way allows the designer to easily migrate to new FPGAs that offer better performance and higher capacities because the OpenCL compiler will transform the same high-level description into pipelines that take advantage of the new FPGAs.
Product Spotlight
APV1111GVY
Panasonic

Panasonic PhotoMOS® Photovoltaic MOSFET High-Power Drivers
| SKU: | |
|---|---|
| Stock: | 3490 |
| Cost: | $3.95 |
